I’m sure we’re all familiar with those download sites riddled with ads that put up their own fake ‘Download’ buttons, but this one takes the cake.
I went to download something, clicked on the one I wanted in the list of packages, it did a ‘Your download will start in…’ countdown, and then…no download started. The area I had just clicked on did get replaced by a big box with one of those fake download ads, though. The package I’d clicked on had been scrolled down the page to below this box, and I clicked on it again, and this time I got a popup window with a Download button…that said ‘Ad’ in the title bar.
I finally noticed that at the bottom of the page there was a “Do you accept this site’s cookies…” prompt and an OK button. Fair enough, they might want me to agree to that before allowing downloads, but that bar hadn’t appeared until after I’d clicked to start the download. And now, trying to navigate to it, I couldn’t actually press it because there was another partially-transparent fake Download ad layered on top of that prompt, where you might inadvertently click on the fake ad part depending on your window size.
After finding the teeny little ‘X’ to dismiss that ad, and agreeing to the prompt, and re-clicking the package again, I finally actually got the download I wanted.
I know these sites have to sustain themselves somehow, but ad fakery to this degree ought to be illegal.
Save Money, Spend Time
I’ve gotten a lot of value out of Humble Bundle’s ebook bundles, which have let me cheaply amass a library of good books and comics that it’ll take me ages to get through. But I do have a few minor complaints…
- It feels like I spend more time fixing up metadata than actually reading them. Books tend to be okay, but the comics are usually missing metadata entirely aside from the title, which is in a compressed format like “dropsofgodvol12.pdf”. Calibre at least has some tools to let you batch convert titles like that into a more reasonable form, but then I still have to fill in the author, artists, genre, etc.
- You can get the books in various formats, but often it’ll present a choice between like a 150 MB PDF, a 254 MB EPUB, and a 18 MB CBZ. Is there a significant quality difference between them? I typically would grab the CBZ for comics, but this CBZ is suspiciously small, so is it very poor quality? Sometimes the bigger file is the higher-quality one, but sometimes it’s just unnecessarily bloated, too. The only way to be sure is to download them all and compare, and which one is best is often different from book to book.
- The ‘batch downloader’ is kind of a joke since it just automatically kicks off an avalanche of individual downloads, which causes a flood of popups to confirm the save location. Some of them inevitably fail to download properly, so I still have to go through manually and verify and redownload them. There’s a bittorrent option, but it’s still a separate torrent file for each book that you have to download.
Some of this might just be my urge to keep things organized, and it’s definitely still worth it to get the bundles, though.
Possibly Crazy
The complex my mother lives in has suffered from bed bug infestations before, so as a matter of course they do some occasional checking of the units for any new signs of bugs. A couple months ago, my mother called me to warn me that they’d found something and treated her unit.
Now apparently it was due to finding just a single spot on her sheets, which isn’t definitive proof of anything, but they did the treatment anyway just as a precaution, since it could have possibly been a sign of bed bugs. Since she’d just travelled to Vancouver recently, she could have possibly picked some up on that trip. It could have possibly been a hotel she stayed at, and since I was on the trip and stayed at the same hotels as well, I could possibly have picked some up and brought them back with me, too.
Now that’s a lot of possiblys, so there’s only a chance I could possibly have bed bugs as well (it’s not even proven that she actually had them to begin with), so I started keeping an eye out for any potential signs of them. And now, about four months after the trip and a couple months of checking the sheets and mattress and some traps, I haven’t seen any definitive signs of them yet, so that’s a pretty good indication that I don’t have them, right?
If only it were that easy to convince the stupid brain…
It’s easy to put the mind into overdrive about possibilities and become paranoid. Oh no, I see a spot on the sheets! …oh, that’s just lint; I tend to wear dark-coloured sleepwear. Oh no, I feel an itch at night! …like I always do in the dry winter climate; I get those itches all day long too, but it’s a lot easier to notice them when you’re lying there trying to blank your mind. Oh no, a tiny little egg-shaped speck! …that crumbles in my fingers because there’s a ton of little bits of random crud everywhere, really. Oh no, spots on my skin! …and I’ve long been prone to random breakouts of acne and rashes, especially again in the winter and when I’ve been eating poorly like I have lately. There’s a ton of ordinary things that make that fear instantly resurface, so it’s never long out of my mind.
And then even when I can recognize all of the above as paranoia, there’s still the lingering thought that, logically, it’s still not proof there aren’t any bugs… They’re sneaky little buggers, I might just not be looking hard enough, the signs could just be hidden away, and how would I even tell if there was an actual bite among the acne, and maybe there’s a secret colony that’s just getting bigger and bigger and… Even getting something like a sniffer dog wouldn’t necessarily help; from what I’ve read there’s still enough of a margin of error to leave lingering doubt of a false negative, and a false positive would be a massive expense and hassle.
There isn’t really any way to prove they aren’t there but for enough time to pass, so the mental war rages on…
Virtual Ride
I wrote before about how it was fairly painless to get around Vancouver by bus thanks to their Compass card system, and when I went to visit my mom, I discovered that Edmonton is doing something very similar with their Arc card system. The weather here lately has made using the ticket machines a bit tricky though, so I finally looked into Calgary’s system, and it…went a different path.
In Calgary’s system, instead of a physical card, you have to use a smartphone app. In the app, you purchase ‘virtual tickets’ ahead of time, and then just before you get on the bus or train, you have to ‘activate’ a ticket in the app. If you’re getting on a bus, you then have to show the QR code the app displays to a scanner on the bus. This is…a bit less convenient than just tapping a card.
You also can’t just load up on a bunch of tickets or put $x into it ahead of time. The virtual tickets expire after only 7 days if you haven’t used them, and you can only buy 5 at a time, so you’re likely going to have to make purchases of them on a regular basis. This then becomes yet another app that wants to hold on to your credit card details for your convenience. (It’s supposed to integrate with ApplePay too, but I’ve had separate troubles getting that working.)
It works, but it’s not great. I guess after several aborted attempts to come up with their own homegrown system, Calgary Transit just gave up and went “look, we’ll just use…those guys” and picked a service already operating in some other cities.
Personal Logistics
I recently took a trip with my mother to Vancouver Island, both to take care of some family business out there and to do a bit of sight-seeing. The main challenge of the trip, though, was just getting around; neither my mother nor I drive, and we needed to get to multiple locations around both the island and the mainland, so just how does one get around a place like that without a car? The obvious ways are taxis, buses, rideshare, and good ol’ walking, but it took a bit of planning to make it all work.
When we arrived in Nanaimo, we needed to get to Duncan. There is a bus between them, but it was already later in the day, and I wanted to make sure we got to the hotel before check-in closed, so we just grabbed a taxi. At over $100 this was by far the most expensive option, so I didn’t want to do this too often, but I just wanted to get there ASAP.
My mom’s mobility is a bit limited these days, but fortunately Duncan itself is fairly small, so walking around was perfectly viable for the places that we needed to reach within Duncan. We also needed to get out to a business in Maple Bay though, and that was way too far to walk, but there’s a bus system within Duncan that runs out that way. I never carry exact change anymore, but we could buy tickets from local shops for the bus and use those instead, so that was no problem. We also wanted to visit Chemainus, and the buses even ran all the way up there.
We needed to get to Tofino next, and that was a bit trickier since it’s a good 3-4 hour trip, so the local bus and taxis weren’t an option. Fortunately there are a couple of other bus services that run up and down the island (the Vancouver Island Connector, and Island Link), and we could take those right to and from Tofino. There’s a gotcha, though: they don’t run every day of the week. I had already booked the hotel in Tofino before I realized that there was no bus at all coming back the day we checked out, so I had to scramble to adjust the booking to ensure we’d be leaving on a day where there would actually be a bus. Scheduling these ahead of time is essential just to make sure you can even get a seat; one of my biggest fears was something going wrong with the booking or the buses somehow and being stranded in Tofino with no easy way back.
Tofino is also a pretty small town that’s extremely walkable, with one exception. We were staying close to the ‘downtown’ section, and the beaches are actually pretty far from there. Within walking distance for me, but not for my mom. Normally there would be a free shuttle bus that would be able to take you pretty close to some of them, but our timing was bad: it stops running for the year at the start of September. So, we wound up calling a taxi to get to and from the beach. Turns out that there’s only one taxi in Tofino, just one car operated by one guy, so we got to see him both directions and chatted a bunch about the area.
We also wanted to stop in Vancouver for a bit to see some family, so we took the bus back to Nanaimo and took the ferry over to the mainland. I was initially uncertain how to handle things from there on, since the ferry drops you off at Horseshoe Bay, a ways away from the city proper, but it turned out to be easier than expected. Horseshoe Bay, West Vancouver, North Vancouver, and Vancouver itself are basically one big integrated transit system, and there were buses going right from Horseshoe Bay all the way downtown, where our hotel was. The only glitch was that I didn’t want to drag our luggage through a transfer onto a second, busier bus for the final leg, so we wound up walking through downtown a bit farther than I’d liked. Dragging two pieces of luggage. Uphill. (I’d forgotten how hilly Vancouver is.) I kind of wish I’d picked a hotel a little bit closer to the ‘main’ bus routes, but I didn’t book as early as I should have so my options were limited.
Getting around Vancouver to see the family was also fairly painless. Again, no exact change, but I was able to use my contactless debit card on any bus, and I bought a pre-loaded ‘Compass card’ for my mom so she just needed to swipe it. Way easier than what we’re trying to roll out in Calgary, where you have to manage and activate virtual ‘tickets’ in a mobile app. Figuring out the routes to take was easy enough through Google Maps, which had a surprising amount of detail about exactly where the buses were. And there wasn’t too much waiting at any point, even though we wound up getting dragged across both West and North Vancouver to chase some of the family down (don’t ask)…
And then on the last day we could simply take the SkyTrain all the way from downtown right out to the airport, where we flew home. So, in the end we only needed to take taxis three times, and managed to bus it the rest of the time. Going into the trip I had a lot of anxiety about successfully navigating all of this, but in the end it was actually a lot easier than expected.
Meet Bob
I occasionally have to work on integrating with APIs for various user directory services, and as part of that I have to create a bunch of fake users with silly names for testing.
These services are also rather hungry for you to sign up for their more advanced/larger volume services though, and some of them are not beyond trying to contact users to try and upsell those services. So, every once in a while, I’ll get an email that literally says “Hello Bob Testuser, I’d like to discuss how we can help you in the mobile space…”
Well, That Was Fun
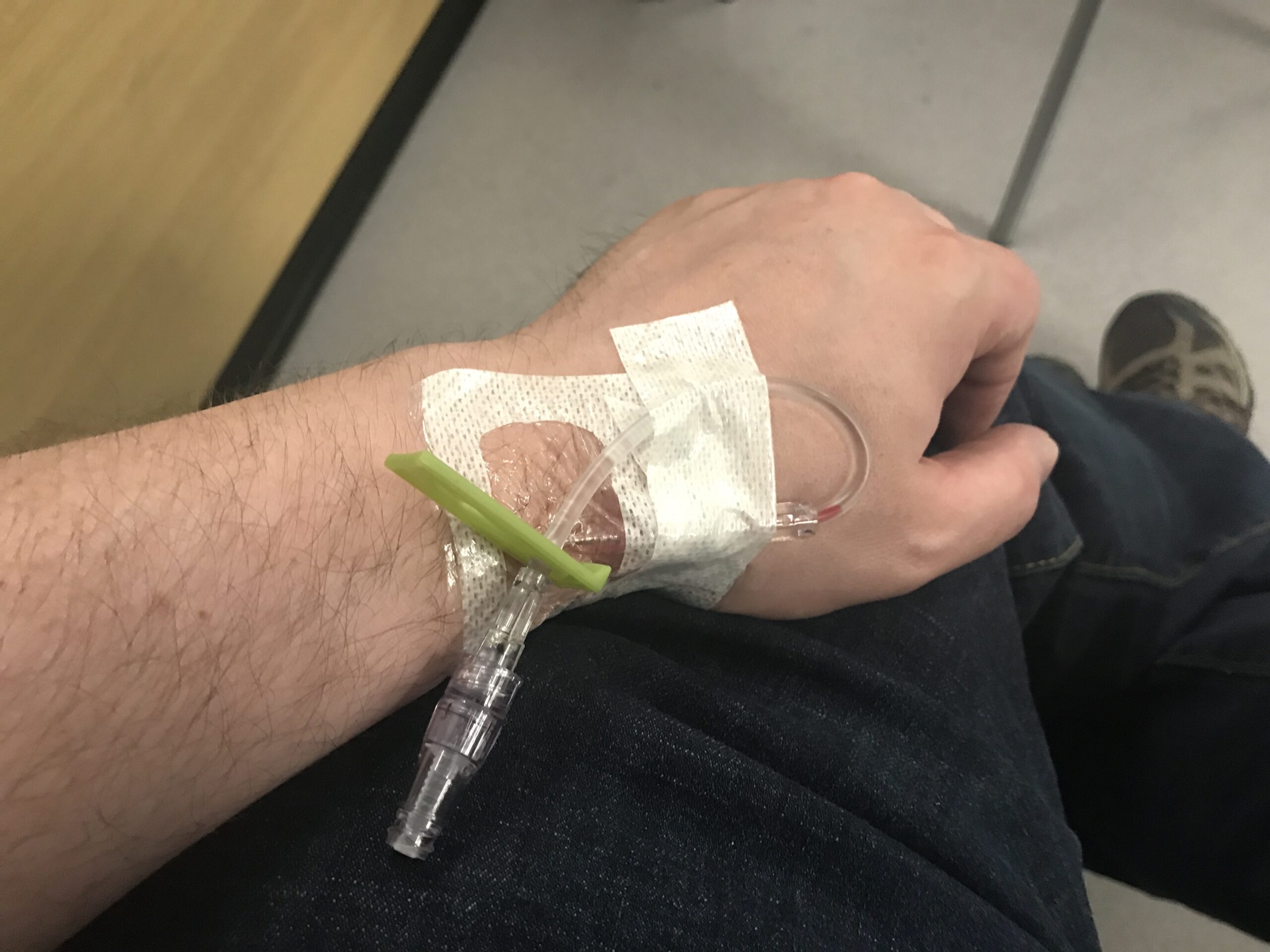
I had my little heart incident last year and haven’t really talked about it since, but throughout 2022 I did a lot of exercising, started eating better, and gradually felt better. By the end of the year I was pretty much feeling back to normal (aside from the bout of COVID). And then 2023 started…
Soon after the start of 2023 I started getting those weird trembling-but-not-really sensations in my legs again, but not consistently; they’d come and go a lot. Over the last month or two I started being able to feel my pulse a lot more strongly, where I’d be aware of it a lot more than I normally would be and could feel it pounding away at night and against my skin in more places. Plus, it felt more erratic at times, suddenly speeding up and slowing back down again for no apparent reason. Along with that my head felt a little, well, not really dizzy or light-headed, but slightly ‘off-kilter’.
And then yesterday, at work, it all kind of hit me at once, as besides all of the above hitting a strong point, I started feeling some tension in my chest and some occasional twinges of pain in my left arm. That was it, I was somewhat actually scared now, I couldn’t put it off any longer and had to get this checked out now, and headed to the ER.
Once at the ER there was a lot of waiting involved because, well, as great as universal health care is, we still perpetually underfund it, and I had to stand around for about an hour in line just to get to the triage assessment. While in line I was feeling bad enough that I started to wonder what would happen if I just collapsed right there in line, but I got through it and they immediately did an ECG after registering me (they do ECGs for a lot of cases, but suspected cardiac cases get to jump the line on that). More waiting until I got called into the back, where they installed an IV, took some blood work, and then a lot more waiting interrupted by checks on vitals and a couple more blood draws.
Eventually, about seven hours later, I got to see the doctor, who took more information, did a physical check, and then he had to inform me that…my heart is doing fine. Sounded fine, the ECG looked fine, the blood work came back fine (slightly above-normal troponin levels, but nowhere near worrying), my heart is actually in a lot better shape than I’d expected.
So, that was kind of a wasted trip, but it’s also a big relief. I still don’t know what the actual problems I’ve been experiencing are caused by yet; I’ll have to seek a more general diagnosis on that with a regular doctor to see if it’s something besides general Getting Olditis. But it’s not my ticker about to explode, at least.
(The doc was pretty cool and we talked for a while about general fitness and exercise and nutrition and such and he had some good advice without being judgy about it. To the point where I suddenly realized that oh jeez, I’ve been tying up this ER doctor’s valuable time blathering on about the shift between WFH and returning to the office and such and I should probably let him get back to work…)
Unnaturally Clean
This is the first week since the pandemic started that I’ll have actually gotten up, showered, and gone to the office all five days of the week. When we were fully work-from-home, why even bother showering more than two or three times a week when you’re not even going to see another person for days at a time, and even when we had to start coming into the office once or twice a week, it doesn’t matter as much when there are only going to be two people there.
So, things are “normal”, I guess. I can still technically work-from-home three times a week, but for the new stuff I’m working on now it really does help to have the beefier multi-monitor PC at the office rather than the single-screen potato I’m currently using at home.
Trying to do things “normally” still feels weird, though. Having to get back to a more rigid wake-up schedule, not having the freedom to take mid-day walks anymore, having to arrange lunch ahead of time instead of just grabbing something from the fridge… I used to do all these things for decades before, but it feels foreign now.
Where Does The Time Go
My new MacBook came with a three month trial of Apple TV. I wouldn’t normally consider subscribing to it since there’s not a lot of stuff on there I’m interested in, but there are a few intriguing-looking shows (Severance, Foundation, For All Mankind), so I figured that I’d just use the free trial period to binge the ones I want and then cancel.
The free trial period is just about to end. Number of episodes I’ve watched of anything on Apple TV: 0
It’s not really Apple TV’s fault, as the same thing is happening with Netflix, really. It often just feels like I don’t have the free time to just sit and watch episodes of something, or I figure I’ll watch it ‘soon’ and that ‘soon’ just never materializes. But at the same time I’ll binge a bunch of random junk on Youtube, including true crime recaps, video essayists, disaster documentaries, video game LPs, etc…
I guess the difference is that the Youtube stuff is a lot more bite-sized and low-investment, something where I can just throw on a random video and when it’s done that’s it, whereas an ongoing TV or streaming series feels like more of an investment I have to be prepared for, so I keep putting it off until I feel more ‘ready’ to take it in. Maybe I just need to set aside a specific time slot specifically for catching up on streaming shows.
Through QA’s Eyes
I have had zero luck getting anyone to take my bug reports seriously lately.
“Hey, your scanning tool throws an error and fails to generate any output when I scan this particular application.”
“Yeah, the archive file contains a file with an invalid filename on Windows. Closed as WONTFIX.”
You’re not even going to try to work around the problem, skip just that one file, so it can at least still scan the rest? I don’t control that app, that came from somewhere else, but I’m stuck with it and it’s my builds that now fail because your scanner can’t handle it.
“Just FYI, your checkout process is a little weird because it wouldn’t let me get past the shipping address until I changed the province to something else and back again, even though the default province was the correct one.”
“Yeah, that’s just how that dropdown control works by default, and we want to make sure people actively make a selection, not accidentally leave it on the default value. Closed as WONTFIX.”
If you want to force people to make a selection, then don’t let the default selection be a valid choice that forces people in Alberta to do an extra little dance, make it “Please select a province:” or such. The default behaviour of the control doesn’t matter, these things are within your power to change!
I wonder if this is how the QA department sees me…
Don’t Call Me
“Oh hey, my old landline number is still in my Paypal profile, I should remove that.
…
There’s no option to remove it…”
Turns out that you *have* to have both a Primary Mobile and Primary Home number, and you can’t remove a Primary number. So, what you wind up having to do is add your mobile number *again* as a Home number, make it the Primary Home number, and then you can remove the old landline number, so you wind up with the same number listed twice.
This is not good UI design, guys!
Oh No!
I should have broken the streak!

Hitting The Streets, Again
I need to get back in the habit of walking again. Things like holidays have a good chance of derailing habits like that, as I spend time travelling and not doing them regularly for a while, and then when I get back I have to force myself back into doing it. The last couple of weeks I’ve only been doing it once every other day or so, which isn’t quite enough. Especially since the holiday overindulgences have caught up with me and I’m feeling some of those old symptoms again…
But I also need to step up the intensity a bit, as it felt like I’d kind of plateaued before. So, today I extended the walk out to include the 14th Street bridge as well, which added about 15-17 minutes to the walk, for a total of about 65 minutes and 6.2km. It also adds some steeper climbs onto the bridge; only brief ones, but it helps get the heart rate up early on. The walks are getting long enough that I’m going to have to queue up some longer podcasts or something though, so I feel like I’m still being a bit more productive mentally as well, not just physically.
The new route also takes me along some paths I’ve never taken before, and it’s weird how strange and new they feel when they’re right next to areas I’ve traversed for ages now. It also gets me some under-the-bridge sights I’ve never seen from these perspectives before:

Nice
Due to Amazon shenanigans, I’ve been browsing around some other e-book stores, and checked in on Kobo today. I was kind of surprised that the “Graphic Novels and Comics” section had its own “Erotica” subsection, and just had to check it, out of curiosity. And once in there, I couldn’t help but notice that the listing of books went out to…69 pages.
Bad Taters
Just had my first failure of trying to resuscitate the freezer-burned old food I had stashed away, with a Stouffer’s Balsamic Chicken entree. It came out with one strip of really tough freezer-burned potatoes, and a cold spot at the bottom of the potatoes, which led to one edge of the chicken patty being cooler than it should have been.
I suspect the problem is that this one had it really bad for moisture having crystallized out onto the plastic film, and I cooked this one in microwave mode instead of oven mode. The water just escaped as steam, and then the potatoes were too dry to pick up enough microwave energy. (The tough strip was probably unsalvageable, though.)
I suspect it would have turned out better if I’d cooked it in oven mode, giving heat more time to penetrate and maybe reabsorb some of the lost moisture. I’ll have to stick to that for the rest of them.
Size Problems
I mentioned before that I needed new cookware for my new oven, and while I was at the Safeway I noticed they sold some little baking pans that were only $8, so I grabbed one. It wasn’t until I got home and could peel the label off that I could read on the back of it that it’s only rated to 415°F. So that’s why it was cheap. I cannot be trusted to remember to put pants on in the morning, let alone remember what the temperature threshold for a random piece of cookware is, and it’s not stamped on the pan itself.
So today I picked up a different set, this time a bundled package of a baking dish, baking pan, and broiling grill, rated to 450°F, which is the highest this oven can do anyway. It’s technically a “toaster oven” set (and, amusingly, it says not to use the broiling grill with a broiler), but whatever, that’s still about the right size that I want.
Except not quite. The baking pan is a bit bigger than the others, and you can put it in the oven, but this beast does something that toaster ovens don’t do: it still turns the turntable in oven mode, and then the pan jams up against the edges. Fortunately there’s a mode setting to disable the turntable, but now that’s another thing I’ll have to remember to set. I foresee a bunch of “*clunk* Oh dangit,” in my future…
Cookin’
I finally got a chance to give my new toy a test in its oven mode, instead of as a microwave. Some notes:
- Some wisps of smoke started to come out of the back while it was preheating, and I panicked and shut it off. After a bit more research, it turns out this is common when using a new oven for the first time, as it burns off various oils and greases and such on the internals from when it was assembled. I guess I’ve never been the first person to ever use a brand-new oven before! It cleared up before too long, but I still kept an eye on it during its first run just in case it burst into flames…
- The area around it gets pretty warm. Well duh, it’s an oven, but I’m not used to having that warmth up on the kitchen countertop. I think I might need to get a separate shelving unit or something for it, to free up some counter space, maybe get it better ventilation, and keep its vents away from potentially getting splashed by the sink.
- I’m going to need some new cookware, since the baking sheets and pans and such that I have are mostly sized for a regular oven. Plus an anti-spatter cover for microwave mode.
- It does an automatic preheat cycle after you set the temperature and timer, but one annoying quirk is that once preheat finishes, it lets you know with a chime, but then immediately starts counting down the timer before you’ve had a chance to actually put the food in. Maybe I’ll just have to set the timer to a minute longer than needed.
- It’s a bit noisy, as it keeps a fan running continuously while operating. About as loud as it is in microwave mode, but in oven mode you’ll be running it for longer.
For its first test, I dug out some frozen stuffed chicken cutlets that have apparently been in the freezer for, uh, six years. They turned out to be a little tough along some of the breading, where moisture had been lost, but were still perfectly edible. As far as being an oven goes, it successfully heated stuff.
There’s still a grilling/air frying mode to test as well, though.
Fry, Baby, Fry
I haven’t had a microwave for a long time. The one I previously had broke probably 15-20 years ago, and I just never bothered to replace it, and I got used to cooking or reheating things on the stove instead.
However, my oven also broke a little while ago, and I’m kind of sick of prepared meals and recipes that increasingly assume you have a microwave, so as my xmas gift to myself, I went and got one of those fancy-shmancy combo air fryer/convection oven/microwave units.

One of the reasons I didn’t replace my old microwave was a lack of space, and unfortunately, with it hogging the right side of the counter, and the dish rack on the left side of the counter, I’m left with this as my meal prep area:

I bought it locally ($250 cheaper than it would have been through Amazon!), and getting it home was also ‘fun’. Carrying it to the cashier didn’t feel so bad, and it’s a fairly short trip to and from the train so I felt pretty confident, but on that last block before home, I probably had to stop and rest my arms four or five times. I’m sure they’ll feel like limp noodles tomorrow.
So far I’ve only used it to warm up some sandwiches and buns, and I still have to see how well it actually works as an oven. Time to see just how bad the freezer-burn is on some of the stuff I have but couldn’t cook anymore when the oven broke…
So This Is What A Popsicle Feels Like
Ugh, I know everyone and their dog’s been complaining, but still, it’s too dang cold (-31C right now, with a reported -44C windchill). Not just outside, it’s rather chilly in my apartment too (the thermostat reports 61F/16C, but I wouldn’t be surprised if it’s actually lower) since the heat in this old building is kinda…weak. With all of the units having their heat constantly turned on, of course, the boiler just can’t keep up, and if I touch the pipe in the heating register, it’s just lukewarm.
I tried having an element on the stove turned on low for a bit, but although it made the kitchen warmer, it didn’t really seem to have much effect on the rest of the place. And I can’t just leave it on all day or I’ll owe the electric company my firstborn. I should probably get a space heater someday so I can put it where I need it, but still, same problem.
At least the pipes won’t freeze, but I’m still going to be grumpy…
Klutz-Dialing
I’d always kind of wondered how “butt-dialing” could even happen, as it seemed extremely unlikely.
But, just now, I went to pick up my phone and fumbled it a bit, and when I turned it around the screen had switched to one of the swipe-to-the-side notification screens, and on that screen was a “Call <last person I called>” shortcut. So yeah, I could see how I you could accidentally reach that.
I put the phone in my pocket, and about a minute later, my mom called me, wondering what was going on. Turns out it had called her, without me even noticing.
Guess it’s easier than I thought!