I’m sure we’re all familiar with those download sites riddled with ads that put up their own fake ‘Download’ buttons, but this one takes the cake.
I went to download something, clicked on the one I wanted in the list of packages, it did a ‘Your download will start in…’ countdown, and then…no download started. The area I had just clicked on did get replaced by a big box with one of those fake download ads, though. The package I’d clicked on had been scrolled down the page to below this box, and I clicked on it again, and this time I got a popup window with a Download button…that said ‘Ad’ in the title bar.
I finally noticed that at the bottom of the page there was a “Do you accept this site’s cookies…” prompt and an OK button. Fair enough, they might want me to agree to that before allowing downloads, but that bar hadn’t appeared until after I’d clicked to start the download. And now, trying to navigate to it, I couldn’t actually press it because there was another partially-transparent fake Download ad layered on top of that prompt, where you might inadvertently click on the fake ad part depending on your window size.
After finding the teeny little ‘X’ to dismiss that ad, and agreeing to the prompt, and re-clicking the package again, I finally actually got the download I wanted.
I know these sites have to sustain themselves somehow, but ad fakery to this degree ought to be illegal.
Category: Geek
Through QA’s Eyes
I have had zero luck getting anyone to take my bug reports seriously lately.
“Hey, your scanning tool throws an error and fails to generate any output when I scan this particular application.”
“Yeah, the archive file contains a file with an invalid filename on Windows. Closed as WONTFIX.”
You’re not even going to try to work around the problem, skip just that one file, so it can at least still scan the rest? I don’t control that app, that came from somewhere else, but I’m stuck with it and it’s my builds that now fail because your scanner can’t handle it.
“Just FYI, your checkout process is a little weird because it wouldn’t let me get past the shipping address until I changed the province to something else and back again, even though the default province was the correct one.”
“Yeah, that’s just how that dropdown control works by default, and we want to make sure people actively make a selection, not accidentally leave it on the default value. Closed as WONTFIX.”
If you want to force people to make a selection, then don’t let the default selection be a valid choice that forces people in Alberta to do an extra little dance, make it “Please select a province:” or such. The default behaviour of the control doesn’t matter, these things are within your power to change!
I wonder if this is how the QA department sees me…
Data Chaos
I really need to stop slacking when it comes to maintaining my PC.
Some time ago, the boot drive on my gaming PC started getting bad blocks, so I swapped it out for a spare laptop drive that I had handy. It was a smaller drive, and not exactly high performance, but it would do in a pinch until I had a chance to replace it properly. I’ve been meaning to do a complete PC upgrade, so it would just have to last until then. Using a smaller drive also meant that I couldn’t restore everything from my backup of the old drive. But that also meant that I couldn’t run any new backups or I’d lose that data that I wasn’t able to restore, and I didn’t have enough room on the backup drive for a parallel backup, so I just turned the backups off. After all this is purely temporary, right?
And now, many months later, I still haven’t done that PC upgrade… Instead of backups, I’d occasionally copy the most important files from under my user profile to some spare space on my Linux server, just in case. And now, I’m getting block errors on my secondary drive… The secondary drive is mostly just game installs, so 95% of it can just be redownloaded from Steam or GOG or wherever, but there is some unique data on there, too. Modded Minecraft installs and worlds, saves for games that don’t put them under the user profile, some game installs that didn’t come from downloads but had to be modded or cracked in order to get them working on modern systems, some other handfuls of miscellaneous files, etc. And since the backups were disabled, these files have gradually grown a bit out of sync with what’s in the backups, and now this drive is potentially failing.
Then I remembered that I actually have a spare 8TB drive that I’d never wound up using for anything. When I ordered it, I was completely reworking how storage was allocated across both the PC and Linux box, but by the time I got it, I realized that I couldn’t use it as a main drive in the gaming PC because I didn’t have enough backup drive space to cover it. I couldn’t use it for storage on the Linux box because I didn’t have a second one to pair with it for mirroring, and I couldn’t use it as a backup drive since I didn’t have a spare enclosure, so it just sat on the shelf of my parts closet.
So now I’m trying to clone all of the data off of both the boot and secondary drives onto this 8TB drive and make it just the single main drive. That won’t be the end of the trouble, though. I still won’t be able to back up this drive, and any data copied from the secondary drive might be affected by bad sectors (I’ll have to keep an eye on any copy errors). And I still need to do the PC upgrade, and when I do so I’ll have to take the data on this drive, the manually copied profile files, and the older backups, and reconcile all of them.
The lesson here is not to put off any important data management tasks, figuring that you can sort them out later on. If I’d just replaced that boot drive with a proper one right away, I’d have been able to keep proper backups going and avoided all this mess.
Airhead
I got tired of complaining about my old laptop (and it was falling apart), so I got a spiffy new M2 Macbook Air. It’s pretty nice. I’m not thrilled about dropping from a 15″ screen to 13″, but eh, I’ll live with it. The Pros are getting out of my price range anyway. I’m still getting used to the keyboard and touch pad just because they’re so different from my old 2010 MBP, but they definitely work well, I just have to break the habit of pressing hard because my old pad had gotten so stiff. Another thing to get used to is that there’s basically no gap between the pad and the keyboard, where I used to rest my fingers a lot.
I figured I’d give Minecraft a whirl and thought I’d be a clever boy and get one of the native ARM Java distributions for setting up modded instances, no Rosetta for me! And then it tries to load native LWJGL libraries, which are still x64 for older Minecraft versions, so back to Rosetta after all… Still, it managed to get 30-50ish FPS under Rosetta with a heavy 1.7.10 modpack, not too shabby. The latest Minecraft version is supposed to be fully native so maybe I can experiment with mixing libraries.
One annoyance so far was that as part of initial setup, it asked what I wanted to sync with iCloud, and I unchecked everything I could. But later on, after migrating files over, I got an email telling me that my iCloud storage was now full. I can’t remember if it was even part of that initial setup, but apparently it had just gone and synced Photos by default. Then, after deleting them in iCloud, you get a scary email about how you’d better redownload the originals from iCloud because they’re no longer on your device, but I double-checked and they are still on the laptop. I think that message is mainly for phones and tablets?
And, it was a bit odd that when moving some files around by command-line, even Terminal would pop up with prompts like “Terminal wants to access the files in Documents. Do you want to allow this?” It only asks once and only for the ‘major’ folders, at least. (Since my MBP was stuck all the way back on High Sierra, I still have to get used to all the OS changes since then too.)
Other miscellaneous bits: dang, it’s small and light. The notch is weird but not a big deal, full-screen apps just don’t use that area. The speakers are definitely louder than my old MBP, where even max volume was a bit too quiet in some videos and streams. I kinda wish the magsafe plug was the L-shaped one instead of straight-on, but that’s just due to how my space is set up. I’m still amazed by being able to open Calibre in four seconds instead of a full minute.
Proving Myself
I just upgraded this server several major distro versions in a row, so hopefully nothing’s too broken…
I also took the opportunity to tighten up some of the security, and in particular e-mail. It’s kinda weird to be running your own local e-mail server nowadays, and it feels a bit too fragile to use it for anything really important, but it’s nice to have a contact point that’s not thoroughly controlled by Google or Microsoft or whoever, and I may as well do it right.
So, now it should be using TLS to encrypt all outbound mail connections, and DKIM signing is set up and a DMARC policy set. Not that I send a lot of e-mails from here, but this should help prove that e-mails from this domain really are legit, and spammers won’t be able to forge addresses from this domain.
It kind of sucks having to SSH into here every time I want to send an e-mail from this domain though, so now do I want to run the risk of running an IMAP server so I can manage e-mail remotely…
Back to Basics
I’ve been feeling stagnant lately. In a lot of ways, but professionally in particular. I’ve been working at the same job now for quite a while, doing fixes and enhancements on old codebases, in only a small team, which imposes various limits. I largely have to stick to the languages already in use in the projects, changes have to fit within the existing, often poor-quality designs, new components and large-scale changes are infrequent, they’re fairly “old-fashioned” applications where newer techniques aren’t really applicable, etc. And with a small team there’s no real feedback as to whether what I’m doing is actually any good or not, so who knows what bad habits and antipatterns I’ve been picking up and relying on.
I’ve never really branched out on my own time, either. Despite having been a computer nerd most of my life, I’m not one of those who spent all day coding at the office, and then went home and coded all evening as a hobby. There’s sometimes a perception that you really should be coding 24/7, work and home, or you’re just crippling your own growth and career, but…eh, I played Minecraft instead.
So, I’ve been thinking that I should probably get back to fundamentals, try and approach things from a fresh perspective and learn anew. I don’t have a specific project to work with yet, so I’ll start with reading some of the books I’ve seen recommended in various places, including:
Structure and Interpretation of Computer Programs – An introductory work, so I’ll be familiar with a lot of it already, but I’m sure there’ll be new stuff as well. And it’ll be from a ‘functional programming’ perspective, which I’ve never really investigated before and is a significantly different way of approaching programming, so I’m hoping to broaden my horizons there.
A Philosophy of Software Design – I know one of my weak points is on how to approach the overall design of a program, since 99% of the time I’m working stuff into an already-existing design. Having to envision and construct the entire design yourself is a lot more intimidating, so I’m hoping for good advice here.
Code Complete, 2nd Edition – A good book focused more on the lower-level nuts-‘n-bolts of programming. I’ve got plenty of experience there, but maybe this can help point out where my habits run contrary to good practice and recommendations. (I’ve actually had this book for a while, but it’s a massive tome and I’ve barely made a dent in it. Oh wait, my copy of this is stuck at the office…)
Sweet 17
Up to now I’ve had to write fairly plain C++ due to having to support a wide variety of environments and compilers, but we’ve recently finally gotten everything in place to support at least C++17 in most of our projects, so hey, it’s time to learn what I can do now!
Structured Bindings
One of the big new features is structured bindings, which can split an object apart into separate variables. It’s not really all that useful on just plain objects, you may as well just reference them by member name then, but it really shines in a few specific scenarios, like iterating over containers like maps, where you can do:
// Old way:
for(auto& iter : someMap)
{
if(iter.first == "something")
doStuff(iter.second);
}
// New way
for(auto& [key, value] : someMap)
{
if(key == "something")
doStuff(value);
}so you can give more meaningful names to the pair elements instead of ‘x.first’ and ‘x.second’, which has always irritated me. It’s a small thing, but anything that improves comprehensibility helps.
The other nice use is for handling multiple return values. Only having one return value from a function has always been a bit limiting; if you wanted a function to return multiple values, you had a few options with their own tradeoffs:
- Kludge it by passing in pointers or references as parameters and modify through them. This in turn meant that the caller had to pre-declare a variable for that parameter, which is also kind of ugly since it means either having an uninitialized variable or an unnecessary construction that’s going to get overwritten anyway.
- Return a struct containing multiple members. A viable option, but now you have to introduce a new type definition, which you may not want to do for a whole bunch of only-used-once types.
- Return a tuple. Also viable, but accessing tuple elements is kind of annoying since you have to either use std::get, or std::bind them to pre-existing variables, which runs into the pre-declared variable problem again.
Structured bindings help with the tuple case by breaking the tuple elements out into newly-declared variables, making them conveniently accessible by whatever name you want and avoiding the pre-declaration problem.
// old and busted:
bool someFunc(int& count, std::string& msg);
int count; // uninitialized
std::string msg; // unnecessary empty construction
bool success = someFunc(count, msg);
// new hotness:
std::tuple<bool,int,std::string> someFunc();
auto [success, count, msg] = someFunc();The downside is that the tuple elements are unnamed in the function prototype, which makes them a bit less self-documenting. If that’s important to you, returning a structure into structured bindings is also a viable option, where you can often use an IDE to see the order of members of the returned struct and their names.
Update: You could also return an unnamed struct defined within the function itself, so you don’t need to declare it separately. You can’t put the struct declaration in the function prototype, but you can work around this by returning ‘auto’. This should give you a multi-value return with names visible in an IDE. The downside is that you can’t really do this cross-module, since it needs to be able to deduce the return type. (Maybe if you put it in a C++20 module?)
auto someFunc()
{
struct { bool success; int count; std::string msg; } result;
...
return result;
}
...
auto [success, count, msg] = someFunc();Optional Values
One of the scenarios I started using structured bindings for was the common situation where a function had to return both an indication of whether it succeeded or not (e.g., a success/failure bool, or integer error code), and the actual information if it succeeded. The trouble when you’re returning a tuple though is that you always have to return all values in the tuple, even if the function failed, so what do you do for the other elements when you don’t have anything to return? You could return an empty or default-constructed object, but that’s still unnecessary work and not all types necessarily have sensible empty or default constructions.
That’s when I discovered std::optional, which can represent both an object and the lack of an object within a single variable, much like how you might have used ‘NULL’ as an “I am not returning an object” indicator back in ye old manual memory allocation days. The presence or lack of an object can also represent success or failure, so now I find myself often returning an std::optional and checking .has_value() instead of separately returning a bool and an object when it’s a simple success/failure result. If the failure state is more complicated or I need to return multiple pieces of information, then structured bindings may still be preferable.
It’s also been useful where a rule or policy may be enabled or disabled, and the presence or lack thereof of the value can represent whether it’s enabled or not. (Though if it can be dynamically enabled or disabled then this might not be appropriate since it doesn’t retain the value when ‘unset’.)
struct OptionalPasswordRules
{
std::optional<int> minLowercase;
...
};
if(rules.minLowercase.has_value())
{
// Lowercase rule is enabled, check it
if(countLower(password) < *rules.minLowercase)
...
}Initializing-if
Another new feature that’s been really useful is the initializing-if, where you can declare and assign a variable and test a condition within the if statement, instead of having to do it separately.
if(std::optional<Foo> val = myFunc(); val.has_value())
{
// We got a value from myFunc, do something with it
...
}
else
{
// myFunc failed, now what
}The advantage here is that the variable is scoped to the if and its blocks, avoiding the common problem of creating a variable that’s only going to be tested and used in an if statement and its blocks but that then lives on past that anyway.
Variant Types
This one is a bit more niche, but I’ve been doing a bunch of work with lists of name/value pairs where the values can be of mixed types, and std::variant makes it a lot easier to have containers of these mixed types. With stronger use of initializer lists and automatic type deduction, it’s even possible to do things like:
using VarType = std::variant<std::string,int,bool>;
std::string MakeJSON(const std::vector<std::pair<std::string, VarType>>& fields);
auto outStr = MakeJSON({ { "name", nameStr },
{ "age", user.age },
{ "admin", false } });and have it deduce and preserve the appropriate string/integer/bool type in the container.
String Views
I’ve talked about strings before, and C++17 helps make things a bit more efficient with the std::string_view type. If you use this as a parameter type for accepting strings in functions that don’t alter or take ownership of the string, both std::string and C-style strings are automatically and efficiently converted to it, so you don’t need multiple overloads for both types. It’s inherently const and compact, so you can just pass it by value instead of having to do the usual const reference. And it can represent substrings of another string without having to create a whole new copy of the string.
bool CheckString(std::string_view str)
{
// Many of the usual string operations are available
if(str.length() > 100) ...
// No allocation cost to these substr operations
if(str.substr(0, 3) == "xy:")
auto postPrefix = str.substr(3);
}
std::string foo("slfjsafsafdasddsad");
// A bit more awkward here since it has to build a string_view before
// doing the substr to avoid an allocation
CheckString(std::string_view(foo).substr(5, 3));
// Also works on literal strings
CheckString("xy:124.562,98.034");
The gotcha is that string_view objects cannot be assumed to be null-terminated like plain std::strings, so they’re not really usable in various situations where I really do need a C-compatible null-terminated string. Still, wherever possible I’m now trying to use string_view as the preferred parameter type for accepting strings.
A lot of this is fairly basic stuff that you’ll see in a million other tutorials around the net, but hey, typing all this out helps me internalize it…
Rusty Robots
I have an old Android tablet, a Nexus 7 from 2012, that I haven’t really used in a long time. I’ve played a few games on it, but I mainly used it for reading comics and doing Duolingo lessons, and I was thinking of doing Duolingo again, so I dusted it off and fired it up again.
The first problem was obvious: it felt sluggish. I had no idea how much crud it had accumulated over time, so I did a factory reset on it to wipe everything out and start fresh.
This led directly to the second problem: it’s old. It was still running Android 4.4.4, and when I went to reinstall apps, a ton of them simply no longer offered installs that would still run on a version this old. I was using some of those apps before, but since I just wiped it, it no longer had the versions I’d installed years ago. The tablet can support 5.1, but when I tried upgrading way back when it first came out, performance was pretty poor and I rolled it back to 4.4.4 and kept it there ever since.
Even with it still on the older version of Android and a fresh reset, it was starting to feel sluggish again, though. It’s not just the operating system itself; the built-in Google apps also get updated and it seems like they’ve bloated enough over time that they just don’t run well on older hardware. So, if it was going to run sluggishly anyway, I figured that I may as well just re-upgrade to Android 5.1.
That solved the app availability problem, as a lot more of them were now available to install, but unfortunately it’s made the performance problems far worse. From hitting the power button to wake it up, it can take 10 seconds or more for the screen to come on. Typing in the PIN, it’s often a second until it acknowledges a tap. It can take another 20 or more seconds for the home screen to appear. Opening the Google Play store can take several minutes, punctuated by being prompted several times “This app isn’t responding, do you want to wait or close it?” Updating an app can take several minutes, even for small apps. Trying to scroll through lists can take a few seconds just for it to respond to the swipe gesture, and scrolls in jarring jumps instead of smoothly. Some of this happened with 4.4.4 as well, but it’s even worse now.
It’s just not usable anymore, for anything, really. My options are to just try and live with that, or revert it back to 4.4.4 again and live with it being sluggish-but-slightly-less-so and fewer apps available. Or, well, an iPad starts to look awfully tempting… It’s just a shame that it feels like a piece of tech from 2012 should at least still be practically useful for something.
And, as I’m typing this, my latest attempt to update apps just ended with:
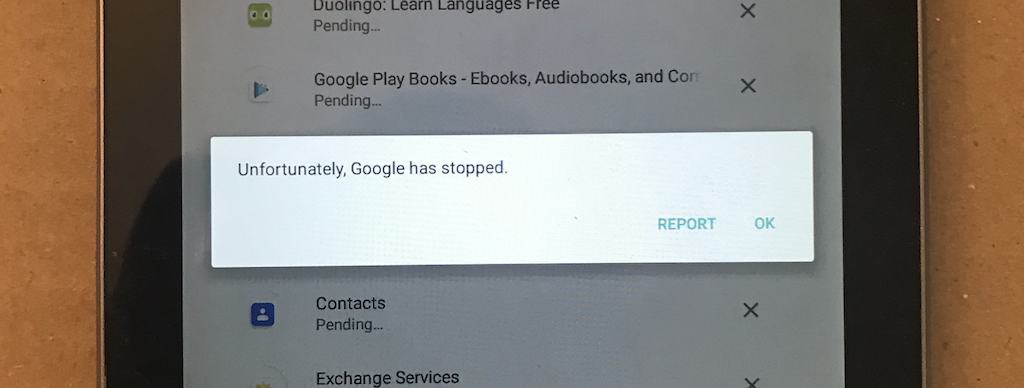
The Need For Power
Bah. A few months ago I started having trouble with games suddenly crashing, often hanging the system and sending the video card fans full blast, with errors in the event log about the display manager crashing. Looked like video card trouble, so I swapped my RTX 2070 out for an old GTX 770 I still had. It seemed better at first, but I’d still get sudden video driver resets that would make things freeze for a few seconds, and the occasional hard system reset. Since it was unlikely that both cards were going bad, my suspicions shifted to the power supply. I want to build a whole new system at some point soon anyway, so I’ve just limped along with it like that for those last couple months now.
Today I just realized that I’d forgotten another factor: at around the same time, I’d hooked up a second monitor, to help make working from home a bit easier. Since I didn’t have the right cabling for the 2070, I hooked the monitor up to the integrated graphics instead. No biggie, since it’s mainly just for displaying some doc and web pages, so it doesn’t need 3D performance. I hadn’t thought about it much since, since it wasn’t the integrated graphics that was crashing, after all. But after I remembered this today, I disabled the integrated graphics and put the 2070 back in and…it’s been fine. It might still be a power supply problem, but I guess something about the extra power draw or stress from enabling the integrated graphics is causing the main video card to glitch out.
So now I can have either working games or a second monitor but not both. Sorry work, but I wanna see what’s new in No Man’s Sky…
Update: Well dangit, after being fine for hours, I had another crash with the 2070. Seems to happen less often, at least? I suspect there may still be a problem with the power supply getting weaker (watt-wise, it should be more than enough), but for now maybe I’ll have to try underclocking it a bit.
Update 2: Ordered and installed a new power supply, and that does indeed seem to have fixed it. The old one was probably overheating, which explains why games would work for a half hour or so and then it would keep crashing even after reboots until it cooled down a bit.
Chubby Templates
One of our DLLs was lacking in logging, so I spent a bit of time adding a bunch of new logging calls, using variadic templates and boost::format to make the interface fairly flexible, much like in a previous post. However, I noticed that after doing so, the size of the DLL had increased from 80kB to around 200kB.
Now that’s not exactly going to break the bank, especially on newer systems where even a VM will probably have 4+ GB of RAM, but that kind of large change still kind of irks me. Modern languages let you do a lot more things a lot more easily, and 99% of the time it’s pointless to try and count every byte of RAM and instruction cycle you’ve spent, but I still kind of have a lurking fear that it might also let me get a bit too…sloppy? If I keep at it, will I eventually turn an application that runs fine on a 2GB system into one that needs 4 or 8 GB?
In this case, from the map file and some tweaking, I can break down this change into various parts:
- 50kB from code pulled in from Boost. Although I’m only directly using boost::format, that class is going to pull in numerous other Boost classes as well. At least this is generally a one-time ‘capital’ cost, and I can now use boost::format in other places without incurring this cost again.
- 24kB of templates generated from the logging interface. Since I’m using a recursive template approach to pick off and specialize certain types, a lot of different variants of the logging function get generated.
- 32kB for new calls to the logging interface. This is across 80 new calls that were added, so each new logging message is adding about 400 bytes of code. That seems like a lot just to make a function call, even accounting for the message text.
- 4kB in exception handling. Not a big deal.
- And 10 kB of miscellaneous/unaccounted for code. Also not going to worry about this too much. Rounding to pages makes these smaller values kind of uncertain anyway.
So, I guess the increase in size does make sense here, though I’m not sure if I can really do much about it. If I switch away from boost::format, I’d lose all its benefits and have to reimplement my own solution, which I certainly don’t want to have to do from scratch. sprintf-based solutions would have to be non-recursive, and that wouldn’t let me do the type specializations I want.
I might look at the assembly and see just where those 400 bytes per call are going, but that’ll probably only save a dozen or so kB at best for a lot of work. It may irk me, but in this case I’ll probably just have to live with it.
Browser Wars
After using Chrome for years now, I figured I’d give Firefox a try again just to give it a fair shake. Although Chrome still works perfectly well for me, it’s a major memory hog and quickly sucks up all the RAM on my laptop, and I’m a bit concerned about privacy issues with it as well.
Unfortunately Firefox still has a quirk that really annoyed me back in the day: when reading a forum thread that contains a lot of images, Firefox takes you to the last-unread-post anchor immediately, but then doesn’t keep you at the same relative position, so the page starts scrolling back up as images load in. So, quite often, I go to read the new posts in a thread, and it positions me somewhere back in posts I’ve already read, not at the actual first new post. Unfortunately, I read an awful lot of forum threads like this…
It also has trouble with Twitch streams, which seem a lot choppier under Firefox and sometimes gets into a state where the audio becomes staticky, and this persists until I reload the tab.
These are annoying enough that I’m probably going to wind up going back to Chrome, alas. I can at least live with having to restart it more frequently to free up memory.
Who Needs Blue Teeth Anyway
I’ve needed to upgrade some audio equipment; my trusty old Sony MDR-CD380 headphones lasted for ages, but have been cutting out in the right ear and the cable’s connection feels a bit flimsy now. I also needed a proper microphone to replace the ancient old webcam that I’d still been using as a “mic” long after its video drivers had stopped working with modern OSes.
I normally anguish for ages over researching models, trying to find the perfect one, but I cut that research short this time. A lot of the “best” gear is out-of-stock pretty much everywhere, and I don’t want to rely on ordering from Amazon too much. Instead, I figured I’d look at what was in-stock in stores in town, and try and get something good and actually locally available. So, after a bit of stock-checking and some lighter research, I finally left my neighbourhood for the first time in this pandemic and headed to a Best Buy.
For the microphone, I picked up a Blue Yeti Nano. Not the best mic ever, but readily available and perfectly adequate for my needs. From some quick tests, it already sounds waaaay better than that old webcam I’d been using. Clearer and crisper, and almost no background hiss, which had been awful with the webcam. It doesn’t have any of the advanced pickup patterns, just cardioid and omnidirectional, but it’s highly unlikely that’ll ever matter to me. It’s not like I’m doing interviews in noisy settings, where you’d really want the “bidirectional” pattern, for example.
For the headphones, I wound up picking up the Sennheiser HD 450BT. I wasn’t really originally considering Bluetooth headphones, since I didn’t want to worry about pairing, battery lifetime, etc., but this model appealed to me as the best of both worlds, as we’ll see in a bit.
I am actually a bit disappointed with the Bluetooth aspect of it. It mostly works…except that there’s a tiny bit of lag on the audio. Not really noticeable most of the time, except when you’re watching someone on Youtube and you can definitely notice a bit of desync between their mouth and what you’re hearing. I suspect my particular really-old Mac hardware/OS combination doesn’t support the low-latency Bluetooth mode, but it’s hard to verify. That wasn’t all, though. If I paused audio for a while, it would spontaneously disconnect the headphones, requiring me to manually reconnect them in the Bluetooth menu before resuming playback, which is really annoying. Playback also becomes really choppy when the laptop gets memory and/or CPU-starved, which happens fairly easily with Chrome being a huge memory hog. None of these are really the fault of the headphones themselves, it’s more the environment I’m trying to use them in, so I don’t think any other model would have done any better.
But, fortunately, I’m not entirely reliant on Bluetooth. The other major feature of these headphones is that you can still attach an audio cable and use them in a wired mode, not needing Bluetooth at all. They still sound just as good, and don’t even consume any battery power in this mode, so I’ll probably just use them this way with the laptop and desktop. I’ll leave the Bluetooth mode for use with my phone and TV, which should work far more reliably.
Speaking of my phone though, the other disappointment is that some of the features of the headphones like equalizer settings can be managed via a mobile app…which requires a newer version of iOS than I have. I could upgrade, but I’ve been reluctant to because that would break all the 32-bit iOS games I have. Dangit. I’ll probably have to upgrade at some point, but I don’t think this will be the tipping point just yet; the headphones still work fine without the app.
These headphones also have active noise cancellation, but I haven’t really had a chance to test it yet. Just sitting around at home, it’s hard to tell whether it’s even turned on or not.
So, overall I’m pretty happy with them so far. The Bluetooth problems aren’t really their fault and aren’t fatal, they sound pretty good, and they’ve been comfortable enough (not quite as comfy as the old Sonys, but those were much bigger cups).
Back In The Stone Age
Woke up to a dead router this morning (RIP ASUS Black Knight, you served well) but at least I was able to find an old one in the old pile o’ parts to sub in for now. Even though it only has 100Mb ports and too-insecure-to-actually-use-802.11b…
I’m not sure what to do now though, since I’ve been thinking of upgrading my internet service and I think either of the potential options are going to force their own all-in-one DOCSIS/Fibre router on me anyway. I’ve always been kind of wary of those since I’ve always used custom firmware for advanced features like static DHCP, dynamic DNS updates, QoS, bandwidth monitoring, etc., and having to use their router might mean giving some of that up. Time to do some research.
From C to Shining C++
I’ve had some extra time to do a bit of code cleanup at work, and I decided a good refactoring of string usage was way overdue. Although this code has been C++ for a long time, the original authors were either allergic to the STL or at least uncomfortable with it and hardly ever used it anywhere; this was originally written a good 15-20 years ago, so maybe it was still just too ‘new’ to them.
In any case, it’s still riddled with old C-style strings. They aren’t inherently bad, but it does tend to lead to sloppy code like:
char tempMsg[256];
setMsgHeader(tempMsg);
sprintf(tempMsg + strlen(tempMsg),
"blah blah (%s) blah...", foo);That’s potentially unsafe, so it really should use snprintf instead:
char tempMsg[256];
setMsgHeader(tempMsg);
snprintf(tempMsg + strlen(tempMsg),
sizeof(tempMsg) - strlen(tempMsg),
"blah blah (%s) blah...", foo);Ugh, that’s ugly. Even after making it safer, it’s still imposing limits and using awkward idioms prone to error (quick, is there a fencepost error in the strlen calculations?). So I’ve been trying to convert a lot of this code to use std::string instead, like:
std::string tempMsg = getMsgHeader();
tempMsg += strprintf("blah blah (%s) blah...", foo); which I feel is far clearer, and is also length-safe (strprintf is my own helper function which acts like sprintf but returns an std::string).
It’s usually fairly straightforward to take a C string and convert it to the appropriate C++ equivalent. The main difficulty in a codebase like this is that strings don’t exist in isolation. Strings interact with other strings, get passed to functions, and get returned by functions, so anytime you change a string, it sets off a chain reaction of other things that need to be changed or at least accommodated. The string you just changed to an std::string is also an output parameter of the function? Welp, now the calling function needs to be converted to use std::string. Going to use .c_str() to call a function that takes plain C strings? Oops, it takes just ‘char *’ and now you gotta make it const-correct…
To try and keep things manageable, I’ve come up with the following guidelines for my conversion:
Don’t try and convert every string at once; triage them.
A lot of strings will be short and set once, used, and then discarded, and they’re not really so much of a risk. Instead, focus on the more complex strings that are dynamically assembled, and those that are returned to a caller. These are the cases where you really need to be wary of length limits with C strings, and you’ll gain a lot of safety by switching to std::string.
Functions that take an existing ‘const char *’ string pointer and only work with that can be considered lower-priority. Since they’re not altering the string, they’re not going to be the source of any harm, and changing them could risk introducing regressions.
Use wrapper functions to ‘autoconvert’ strings.
If you have functions that already take ‘const char *’ strings as parameters and work perfectly fine, you don’t necessarily need to convert the whole thing right away, but it can help to have a wrapper function that takes an std::string and converts it, so that you can use std::strings in the callers.
void MyFunc(const char *str)
{
...
}
void MyFunc(const std::string& str)
{
MyFunc(str.c_str());
}Now functions that call MyFunc can be converted to use std::string internally and still call MyFunc without having to convert MyFunc as well, or having to pepper the caller with .c_str() calls.
This can get tricky if you have functions that take multiple string parameters and you still want to be able to mix C-style and std::string as parameters. If it’s only a couple of parameters you can just write all possible combinations as separate wrappers, but beyond that it gets unwieldy. In that case you could use template functions and overloading to convert each parameter.
void MyFunc(const char *foo1, const char *foo2, const char *foo3, const char *foo4)
{
printf("%s %s %s %s\n", foo1, foo2, foo3, foo4);
}
const char *ToC(const char *x) { return x; }
const char *ToC(const std::string& x) { return x.c_str(); }
template<typename S1, typename S2, typename S3, typename S4>
void MyFunc(S1 foo1, S2 foo2, S3 foo3, S4 foo4)
{
MyFunc(ToC(foo1), ToC(foo2), ToC(foo3), ToC(foo4));
}
int main()
{
MyFunc("foo", "bar", "baz", "blah");
MyFunc("aaa", std::string("fdsfsd"), "1234", "zzzz");
MyFunc(std::string("111"), "222", std::string("333"), std::string("444"));
return 0;
}It’s still kind of awkward since it needs helper overload functions polluting the namespace (I’d prefer lambdas or something nested function-ish, but I can’t see a good way to do it that isn’t ugly and difficult to reuse), but it avoids having to write 2^N separate wrappers.
Don’t get too fancy while converting
std::string will let you be more flexible when it comes to string manipulation, and you’ll probably no longer need some temporary string buffers, some string assembly steps can be combined, sanity checks can be removed, other string operations can be done more efficiently in a different way, etc. But if you try and make these changes at the same time you’re converting the string type, you could risk messing up the logic in a non-obvious way.
Make the first pass at string conversion just a straight mechanical one-to-one conversion of equivalent functionality. Once that’s done and working, cleaning up and optimizing the logic can be done in a second pass, where it’ll be clearer if the changes maintain the intent of the code without being polluted by all the type change details as well.
There are some other caveats to watch out for, too:
Beware of temporaries.
Wherever you still need C-style strings, remember that a returned .c_str() pointer only remains valid as long as the std::string still exists and is unchanged, so beware of using it on temporary strings.
const char *s = (boost::format("%s: %s") % str1 % str2).str().c_str();
SomeFunc(s); // WRONG, 's' is no longer validHowever, the following would be safe, since the temporary string still exists until the whole statement is finished, including the function call:
SomeFunc((boost::format("%s: %s") % str1 % str2).str().c_str());Of course, most people already knew this, but the odds of inadvertently introducing an error like this goes way up when you’re changing a whole bunch of strings at once, so it’s worth keeping in mind.
Variadic functions are annoying
Unfortunately, ye olde variadic functions don’t work well with std::string. It’s most often used for printf-style functions, but an std::string doesn’t automatically convert to a C-style string when passed as a variadic parameter, so you have to remember to use .c_str() whenever passing in an std::string.
There are non-variadic alternatives like boost::format that you might want to prefer over printf-style formatters, but if you’re stuck with printf-style functions for now, make sure you enable compiler warnings about mismatched printf parameters and set function attributes like GCC’s __attribute__ ((format …)) on your own printf-style functions.
If you have boost::format available, and a C++17 compiler, but don’t want to convert a bajillion printf-style parameter lists, you could use a wrapper like this with variadic templates and fold expressions:
template<class... Args>
std::string strprintf(const char *format, Args&&... args)
{
return (boost::format(format) % ... % std::forward<Args>(args)).str();
}With this you can then safely pass in either C-style or std::string values freely. Unfortunately then you can’t use printf-format-checking warnings, but boost::format will be able to do a lot more type deduction anyway.
Performance is a concern…or is it?
C-style strings have pretty minimal overhead, and with std::strings you’ve now got extra object memory overhead, reallocations, more temporary objects, generated template functions, etc. that might cause some performance loss. Sticking with C-style strings might be better if you’re concerned about performance.
But…with modern optimizers and move constructors, return value copy elision, small string optimizations in the runtime, etc., the performance penalty might not be as bad as you think. Unless these strings are known to be performance-critical, I think the safety and usability value of std::strings still outweighs any slight performance loss. In the end, only profiling can really tell you how bad it is and it’s up to you to decide.
Ah, C++…
(edit: Of course it wasn’t until after writing this that I discovered variadic macros, available in C++11…)
While working on some old code, there were a bunch of rather cumbersome printf-style tracing macros where you had to make sure the name of the macro matched the number of parameters you wanted to use. E.g., use TRACE1(“foo: %s”, s) for one format parameter, use TRACE2(“foo: %s %d”, s, x) for two parameters, etc. It was always annoying having to make sure you picked the right name, corrected it whenever the parameters changed, and so on.
I can understand why someone created these macros in the first place. They exist as a shorthand for another variadic tracing function with a much longer name, to keep tracing calls short and snappy, or to redirect them to nothing if you want tracing disabled, but that presents a few challenges. An inline function would preserve the preprocessor-controlled redirection, but you can’t simply have a function with a shorter name call the other function because variadic functions can’t pass on their arguments to another variadic function. You could just create a #define to map the short name to the longer name, like “#define TRACE GlobalTraceObj::CustomTraceFunc”, but that risks causing side effects in other places that use ‘TRACE’ as a token, and doesn’t let you eliminate the call if desired. A parameterized macro avoids that problem, but only works for a specific number of parameters, and hence you wind up needing a different macro for each possible number of arguments.
I figured there had to be a better way and hey, now that I have newer compilers available, why not try C++11 variadic templates? They do let you pass variadic arguments on to another variadic function, which is exactly what’s needed, and it can still be conditional on whether tracing is enabled or not!
template<typename... Args>
inline void TRACE(const char *format, Args... args)
{
#ifndef NOTRACE
GlobalTraceObj::CustomTraceFunc(format, args...);
#endif
}And it worked perfectly, now I could just use TRACE(…) regardless of the number of parameters.
Except, I got greedy… Another nice thing is to have the compiler do consistency checks on the printf-style formatting string and its arguments, which you can do with compilers like GCC with a function attribute like on the main tracing function:
static void CustomTraceFunc(const char *format, ...)
#ifdef __GNUC__
__attribute__ ((format (printf, 1, 2)))
#endifI wanted that same checking on the TRACE wrapper function, but it turns out that at least at the moment, you can’t apply that same function attribute against a variadic template function; GCC just doesn’t recognize the template arguments as the right kind of variadic parameters that this attribute works on. Oh well.
I really wanted that consistency checking though, so in the end I abandoned the variadic template approach and just wrote TRACE as a plain old variadic function, which meant having to modify the other tracing functions to use va_lists instead, but that wasn’t too big a deal. If I didn’t also have control over those other functions, I would have been stuck again.
#ifdef __GNUC__
__attribute__ ((format (printf, 1, 2)))
#endif
inline void TRACE(const char *format, ...) {
#ifndef NOTRACE
va_list args;
va_start(args, format);
GlobalTraceObj::CustomTraceFuncV(format, args);
va_end(args);
#endif
}
static void GlobalTraceObj::CustomTraceFuncV(const char *format, va_list args)
...Wrestling Hercules
For some reason I got it into my head last weekend to set up a Linux s390x instance, using the Hercules emulator. We do some mainframe stuff at work, and we have a couple instances of z/Linux already, but they’re in Germany and managed by another team, so maybe it would be neat to have our own local instance, even if emulated? Although I’ve done some work on the mainframe before (mainly on the USS side), I’m hardly an expert on it, but how hard could it be?
So fine, I set up a Fedora Server 30 VM as the emulator host and installed Hercules onto it and set up a basic configuration, per various guides. There are a handful of s390x Linux distros but I figured that Debian would make for a nice, generic baseline instance, so I grabbed the Debian 9.9 s390x install DVD image.
Problem #1: It wouldn’t boot. IPLing from the DVD image just spit out a few lines of output and then hung. After some digging, this had been noted on the Debian bug mailing list, but with no resolution or workaround.
Figuring that maybe the distro was too new for the emulator, I grabbed a Debian 7 install DVD (there was no listing for an s390x version of 8 on the main download pages) and hey, it actually booted and started going through the install process.
Problem #2: It doesn’t actually install from the DVD. Even though it has all of the packages on it, the s390x installer still goes and gets them from the network, and the networking wasn’t working. It could ping out to other networks, but DNS and HTTP wouldn’t work. After way too much fiddling around, I finally figured out it was an iptables ordering problem, and using ‘iptables -I …’ instead of ‘iptables -A …’ on the forwarding commands worked around that and got networking going.
Problem #3: The mirrors didn’t have Debian 7. Unfortunately I didn’t realize beforehand that the Debian 7 packages were no longer available on the mirror sites, so the installer couldn’t proceed. With a bit of searching, I found that there actually was a Debian 8 disc for s390x though, so I got that and gave it a try.
Problem #4: The mirrors don’t really have Debian 8, either. At least not the s390x packages, just the other main platforms. At this point it looked like there just wasn’t a path to get any version of Debian working, so I started trying some of the other distros.
Problem #5: The other distros aren’t quite as easy to install. Newer Fedora releases hung, older Fedora releases didn’t quite behave as expected and it was unclear how to make installation proceed, and openSUSE was still experimental and unclear how to install it. I even tried Gentoo, which seemed to work for a while after starting up before hanging at a point where it was unclear if it was grinding away at something intensive or not, and I let it sit there for two days before giving up on it. So yeah, not much luck with the other distros either.
Searching around for more info, I found that there were some newer versions and forks of Hercules that potentially fixed the hang problem, so it was time to give Debian 9.9 another try, using the Hyperion fork of Hercules.
Problem #6: Hyperion’s still a bit buggy. It compiled and installed just fine, but some of the permissions seemed incorrect and I had to run it as root. Even before IPLing it was extremely sluggish (sending the load average up to over 8), and trying to IPL the Debian disc just froze in an even earlier spot. So much for that.
Then I gave the ‘spinhawk’ fork of Hercules a try, and…hallelujah, everything’s gone smoothly since. It IPLed from the Debian image fine, it could find the mirrors and download packages, partition the disk, etc., and I now have a fully installed and working s390x Linux system.
Was it worth the hassle? Eh, probably not, I’m still better off doing any coding for work on our actual non-emulated z/Linux systems. It was interesting just to experiment and play around with for a bit, though.
Lack of Mac
I’m still using a 2010 Macbook Pro as my main day-to-day system, and I’ve been meaning to upgrade for a while now since both RAM and disk space have been getting tight, and although I could slap a bigger hard drive in it, the RAM can’t be upgraded any further. May as well just upgrade the whole shebang at once anyway.
Except…I haven’t been too happy with the available choices lately. The newer MBPs have a new type of ‘butterfly’ keyboard that’s widely hated and fairly fragile, I don’t know if I’d like the lack of a physical ESC key (especially as a ‘vi’ user), you need dongles for fairly common connection types now, etc. But, perhaps worst of all, they’re just really friggin’ expensive!
I paid about $2200 for my current MBP, and then upgraded the memory and hard drive later on, but they’re non-upgradable now, so you have to buy the long-term specs you want right up-front, and those upgrades are ludicrously expensive. I currently have a 500GB hard drive, but I’m always running out of space and cleaning things up, so I’d like to go to 1TB for a new system. Bumping the storage up to 1TB adds $720 to the price, even though a decent 1TB M.2 module costs around $300; that’s a hell of a markup!
Putting together a new MBP that would actually be a one-step-up upgrade for RAM and hard drive, the total price starts at $3900. If I drop down to a 13″ screen (which I’d rather not do for a system I use so heavily), it’s still around $3400.
That’s just too much for me right now, especially if it’s going to have an awful keyboard. It’s not like they’re going to get any cheaper in the future though, so I’m still not sure whether to just suck it up, wait even longer, or just start looking at Windows laptops. There are plenty of Lenovos with half-decent specs in the $2200-$2500 range…
100% Guaranteed Genuine Drivel
After putting it off way too long, I finally have a TLS certificate set up for all the web stuff I host here, courtesy of Let’s Encrypt and Certbot.
It’s not like I’m particularly worried about attackers hijacking the site (because it has so much influence…), but the winds are blowing towards HTTPS-everywhere, and no point in getting left behind. Certbot makes it pretty painless, at least, though I’m sure there are some older broken images or links that I’ll have to clean up over time. Any non-HTTPS links on or to the site should automatically redirect to the appropriate HTTPS URL.
Time To Kill My Brain
Well, after 10+ years of using my dinky little computer monitor as a “TV” (meant to be a temporary measure after my old tube TV broke), I finally have a proper TV again. It’s three weeks late thanks to shipping shenanigans, but I’d rather not dwell on that…
It’s not OLED, which is still kinda pricey, but it is 55″, 4K HDR, and has local dimming, so the quality’s really nice and it should remain futureproof for quite a while yet. I may have to do some calibration, but God of War already looks amazing on it.
Right now I have the cable box, PS3, and PS4 hooked up to it, and I also want to hook up the PC so I can play PC games on it, but I’ll need to get a longer HDMI cable for that. I don’t have the 360 hooked up since I don’t have the right cables (it’s one of the early non-HDMI 360s), and I could hook up the Wii with component cables, but they’re not a priority right now. If I run out of HDMI ports, I have an HDMI auto-switcher so some of the consoles could share a port, if needed.
It also finally let me clean up a whole mess of audio cabling. I used to have to split out the audio signals from all the boxes, route them through a switcher, and then through a PC, resulting in a ton of RCA audio cables and proprietary console A/V connectors strewn all over, but now everything’s just HDMI so all that cabling is gone.
The only quibble so far is that the UI (Android TV) is kinda clunky and slow, it can take up to 5 seconds for some of these menus to come up, but hopefully I won’t have to use it too much. Oh, and the motion smoothing they enable by default is total garbage (Mad Max Fury Road happened to be on TV, and it feels so weird with it enabled), but it’s easily disabled.
Now maybe I’ll actually watch more TV and movies now that they don’t have to fight with the PC…
Internal, External, Who Cares
The Dell I ordered to replace my old Linux box arrived, and after spending a few hours setting it up, it’s amazingly tiny, whisper-quiet, and works pretty well! It spooked me a bit when it suddenly started making sound, as I didn’t realize it has a speaker built right into the case.
It also doesn’t have room for the 8TB internal storage drive. Whoops! I probably misread the storage configuration information when I ordered it and it comes with two internal 2.5″ bays, and no 3.5″. It was super-easy to get at those bays though, so I took the old SSD and added it to the one the system came with.
I think I can still work with this, though. It’s so small that there’s plenty of space to put the storage drive in an external enclosure instead. Just from testing with the two external drives I have right now, I can get 150MB/s out of the USB3 ports (versus the 15-20 I was getting on the old system), so speed certainly won’t be a problem. It’ll just be another wall-wart to deal with…
And after using Ubuntu for probably close to 10 years, I’m giving Fedora a try instead. Just for something different, and I’d been seeing recommendations for it in a few places now. I’ll still mostly be using it via SSH, so there probably won’t be too much difference in practice.